One of the most trivial tasks for data replication is to define a replica of the table with just a subset of the rows from the source table. For example we would like just to replicate the ACCOUNTS table with some type (one column has some defined value). If you want to replicate that using Oracle GoldenGate and the account type may be modified then this is one of the most difficult tasks to achieve… Let’s find out why.
1. Basic filtering scenario
In this post I am going to discuss a very simple case. Everybody who used before SAP (Sybase) Replication Server would find this task very easy. Let’s have the following schema:
CREATE TABLE tab ( col1 NUMERIC PRIMARY KEY, col2 VARCHAR2(10) NOT NULL, col3 NUMERIC NOT NULL );
I have deliberately removed here and in the whole post the schema of the tables to make the code cleaner.
And let’s replicate this table using :
ADD TRANDATA tab, COLS(col2)
It’s a better idea to ADD TRANDATA on the filtered column (col2) instead of using fetchcols (what the documentation suggests). This way will be much faster and would not require a call to the database every time a row appears.
The extract param has:
TABLE tab;
The replicat param has:
TABLE tab, FILTER (@STREQ(col2, 'x'));
I have put there FILTER clause deliberately in the Replicat param file – not the Extract, since I want all rows in the trail – they may be needed for other targets.
Oracle GoldenGate will work like this:
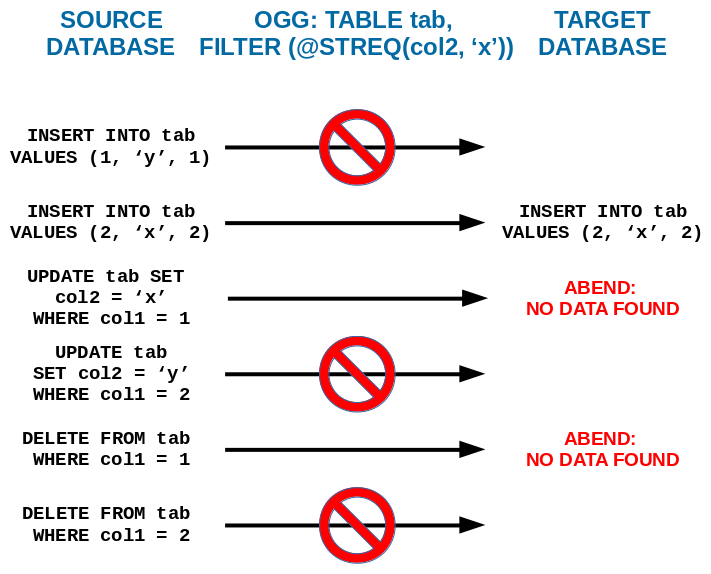
In contrast SAP (Sybase) Replication Server for at least 20 years is able to handle this situation and replicates like this:
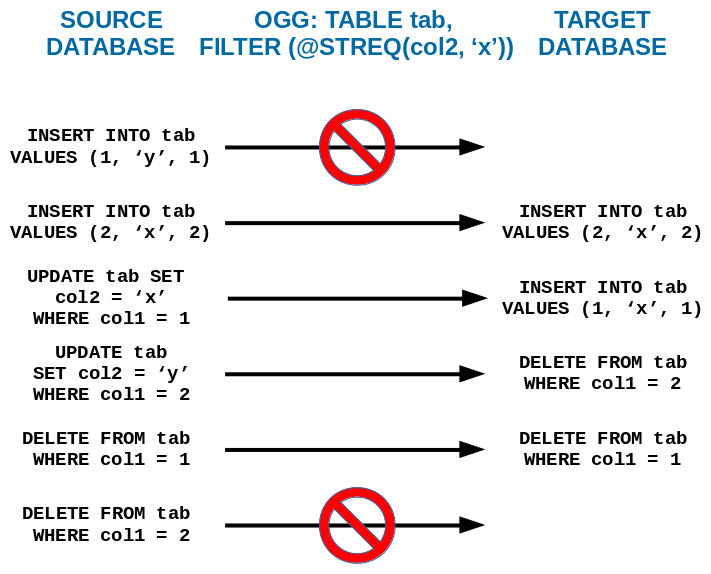
Of course to achieve the result I would be using Replication Server, not OGG commands (create replication definition, subscription with WHERE clause, etc.).
OGG by default does not work this way and some hacking to achieve the goal.
For somebody that has never written scripts for OGG this would be obvious how it should behave of the replication tool. Let’s look into the details how we can achieve the proper result.
2. Goals
As seen in the the example above to achieve proper filtering we need to replicate the UPDATE command in a different way:
- If the row before the UPDATE did not match the WHERE/FILTER rule, and after UPDATE it does – then it should be replicated as an INSERT command
- If the row before the UPDATE matched the WHERE/FILTER rule, and after UPDATE it did not – then it should be replicated as an DELETE command
We need to be sure that all the required column data is in the REDO LOG so that the Extract process would be able to grab it.
We need to be sure that we write all the required columns values go to the Trail file.
That’s all what is needed here. Let’s get to work.
3. Supplemental logging
The documentation advises to use the FETCHCOLS (kinda strange) parameter for the TABLE/MAP clause. But it is not only ineffective and only causes problems. That would be not enough to convert UPDATE to INSERT. Actually the best solution is to configure the source database to write all the required data to the REDO LOG. We can achieve that with the command:
ADD TRANDATA tab, ALLCOLS
This way we add extra load to the source database, but it is the most reliable approach.
4. Extract parameters
A while ago I have made an analysis about what is the Extract process writing to the Trail file for OGG 12.2/12.3.
To be sure that the Trail contains all columns for UPDATE and DELETE commands the following parameters have to be used for the Extract:
LOGALLSUPCOLS UPDATERECORDFORMAT COMPACT
5. Replicat Parameters
For the Replicat it necessary to make transitions for the UPDATE command:
ALLOWDUPTARGETMAP IGNOREUPDATES MAP tab, TARGET tab, FILTER (@STREQ(col2, 'x') = 1); GETUPDATES IGNOREINSERTS IGNOREDELETES -- replicate UPDATE as INSERT - updating from non matching to matching - so it has to be inserted: INSERTUPDATES MAP tab, & TARGET tab, & FILTER (@STREQ(col2, 'x') = 1 AND @STREQ(@BEFORE(col2), 'x') = 0); NOINSERTUPDATES -- replicate UPDATE as UPDATE - updating a matched row - just run regular update: MAP tab, & TARGET tab, & FILTER (@STREQ(col2, 'x') = 1 AND @STREQ(@BEFORE(col2), 'x') = 1); -- replicate UPDATE as DELETE - updating from matching to non matching - so it has to be deleted: MAP tab, & TARGET tab, & FILTER (@STREQ(col2, 'x') = 0 AND @STREQ(@BEFORE(col2), 'x') = 1), & SQLEXEC (id qry, QUERY 'DELETE FROM tab WHERE col1 = :oldcol1', PARAMS (oldcol1 = col1)), & EVENTACTIONS (IGNORE); GETINSERTS GETDELETES
Actually the code is self-explainable so it does not require any kind of comment.
And this is just for one table and one rule. Happy coding if you want to filter more than table this way.
Hi.. thanks for your post.. I have a following question
Let’s say In source DB, I have a table with 10 columns, C1, C2… C10.. and I have same number of columns in target as well, and the GG is setup to replicate all the changes in this table from source to target using the same primary key column on both sides.
But in target, we are really interested in first 7 columns, and last 3 columns (C8, C9, C10) are not used..
But in source we get huge number of updates in those 3 columns (there is an update statement which updates only those 3 columns, no other column values are changed in SET clause of the update statement)
As of now, as per GG, it is still a change and it is trying to replicate all those changes to target.
my question is, If I configure to ignore those 3 columns, the changes made by that update statement will be completely ignored?
just to give you an perspective, we get about 600k rows in that table per day, and we do see about another 200-300k updates on required columns, but we see about 10M updates on those 3 columns which we are not required. because of that much volume, we see a huge delay in having the required data in target..
Looking for some options at golden gate level to optimize this replication..
We are thinking to make a change in application to not have that 10M updates, but it may take a while to have that change implemented in source database application.. (it may not be event approved to make that change).