Oracle at some point of decided that users might want to replicate the changes from the database to other targets. What they noticed, that the architecture of the database did not allow easy replication since the redo log did not contain information that would allow to identify the exact row, that has been modified.
The solution was to add supplemental information to the UNDO (op 5.1) part of the redo log vector (to the redo log).
This information can include additional information about columns that were not affected by DML operation and ROWID of the modified row.
All replication tools (including OpenLogReplicator) require to configure the source database to include this additional supplemental logging information in the redo log. Without it you can’t identify the exact row just by reading the redo log data. Many users ask in this moment:
How much space does supplemental redo log take in the redo log file?
Well… the database will not tell you that. There is no way of finding that out.
You can of course create 2 test scenarios – and repeat the whole test. But having some redo log file from production there is no way the database can tell you that information.
There are some ways of estimating it. Some some people tell you to make your calculation by yourself, but this is very difficult to estimate without technical knowledge about the redo log file format.
So far at least.
Can’t OpenLogReplicator tell you that?
Till yesterday the answer was: no. But with today’s commit (version 0.7.1) – the answer is: yes – it can.
After enabling trace performance option (“trace2”: 32) additionally to the information about performance and log speed processing you will also get information about supplemental log group. The sum will include:
- The cost of having more elements of the redo log vector (increased size – 2 bytes per every element)
- The size of the supplemental log header
- The size of the supplemental log column list
- The size of all columns in the supplemental group
This information will be exactly calculated and printed in the output.
Now I can now know how much space did supplemental redo group take in a particular file?
Yes you can now. Let’s find out.
For this exercise I will do the following task. Let’s generate 2 redo log files – one with some basic PK information and one with full logging of all columns.
My database is version 12.1.0.2 and has just set options:
ALTER DATABASE ARCHIVELOG;
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;This is a very typical approach – with minimal supplemental logging.
Let’s run this test with 3 cases:
- test 1: table with no supplemental logging (just minimal set at the database level)
- test 2: table with primary key supplemental logging
- test 3: table with full supplemental logging
drop table USR1.ADAM1 cascade constraints;
drop table USR1.ADAM2 cascade constraints;
drop table USR1.ADAM3 cascade constraints;
create table USR1.ADAM1(
PK numeric(20),
A numeric(20),
B char(50),
C char(50),
D char(50)
);
alter table USR1.ADAM1 ADD constraint ADAM1PK primary key(PK);
create table USR1.ADAM2(
PK numeric(20),
A numeric(20),
B char(50),
C char(50),
D char(50)
);
alter table USR1.ADAM2 ADD constraint ADAM2PK primary key(PK);
ALTER TABLE USR1.ADAM2 ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;
create table USR1.ADAM3(
PK numeric(20),
A numeric(20),
B char(50),
C char(50),
D char(50)
);
alter table USR1.ADAM3 ADD constraint ADAM3PK primary key(PK);
ALTER TABLE USR1.ADAM3 ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
ALTER SYSTEM ARCHIVE LOG CURRENT;
-- test1
select sequence# from v$log where status = 'CURRENT';
begin
for i in 1 .. 1000 loop
insert into USR1.ADAM1 values(i, 10000, 'b', 'c', 'd');
commit;
end loop;
end;
/
begin
for i in 1 .. 1000 loop
update USR1.ADAM1 set B = 'X' where A = i;
commit;
end loop;
end;
/
begin
for i in 1 .. 1000 loop
delete from USR1.ADAM1 where A = i;
commit;
end loop;
end;
/
ALTER SYSTEM ARCHIVE LOG CURRENT;
-- test2
select sequence# from v$log where status = 'CURRENT';
begin
for i in 1 .. 1000 loop
insert into USR1.ADAM2 values(i, 10000, 'b', 'c', 'd');
commit;
end loop;
end;
/
begin
for i in 1 .. 1000 loop
update USR1.ADAM2 set B = 'X' where A = i;
commit;
end loop;
end;
/
begin
for i in 1 .. 1000 loop
delete from USR1.ADAM2 where A = i;
commit;
end loop;
end;
/
ALTER SYSTEM ARCHIVE LOG CURRENT;
-- test3
select sequence# from v$log where status = 'CURRENT';
begin
for i in 1 .. 1000 loop
insert into USR1.ADAM3 values(i, 10000, 'b', 'c', 'd');
commit;
end loop;
end;
/
begin
for i in 1 .. 1000 loop
update USR1.ADAM3 set B = 'X' where A = i;
commit;
end loop;
end;
/
begin
for i in 1 .. 1000 loop
delete from USR1.ADAM3 where A = i;
commit;
end loop;
end;
/
ALTER SYSTEM ARCHIVE LOG CURRENT;I have run the whole script as a batch and run together – to include least possible garbage from background processes.
My code apart from execution information about PL/SQL blocks returned 3 sequences of redo log files: 945, 946, 947:
-rw-rw----. 1 500 500 1276928 Aug 26 07:29 o1_mf_1_945_hncwss83_.arc
-rw-rw----. 1 500 500 1280000 Aug 26 07:29 o1_mf_1_946_hncwsw76_.arc
-rw-rw----. 1 500 500 1277440 Aug 26 07:29 o1_mf_1_947_hncwsz8z_.arcLet’s examine those 3 redo log files:
At this moment nothing has been configured earlier. OpenLogReplicator has not been used. Let’s create config file OpenLogReplicator.json to work with batch mode. This mode allows just to analyze particular redo log files given in the list. It will not connect to the database. It will stop once all processing is finished:
{
"version": "0.7.1",
"trace2": 32,
"sources": [
{
"type": "ORACLE",
"alias": "S1",
"name": "ORA12102",
"mode": {
"type": "batch",
"redo-logs": [
"/opt/fra/ORA12102/archivelog/2020_08_26/o1_mf_1_949_hncy24qf_.arc",
"/opt/fra/ORA12102/archivelog/2020_08_26/o1_mf_1_950_hncy26bo_.arc",
"/opt/fra/ORA12102/archivelog/2020_08_26/o1_mf_1_951_hncy29cf_.arc"
]
}
}
],
"targets": [
{
"type": "KAFKA",
"format": {"stream": "JSON", "topic": "O112A", "test": 1},
"alias": "T2",
"source": "S1"
}
]
}The task here is just to analyze the log files and count supplemental redo log size.
I need also to prepare ORA12102-schema.json. This file is automatically created in online mode and you can just modify the values, or create by yourself:
{"database":"ORA12102","big-endian":0,"resetlogs":1046365499,"activation":4234781617,"database-context":"ORA12102","con-id":0,"con-name":"ORA12102","db-recovery-file-dest":"\/opt\/fra","log-archive-dest":"","log-archive-format":"%t_%s_%r.dbf","nls-character-set":"AL32UTF8","nls-nchar-character-set":"AL16UTF16","online-redo":[],"schema":[]}And now let’s run OpenLogReplicator:
OpenLogReplicator v.0.7.1 (C) 2018-2020 by Adam Leszczynski (aleszczynski@bersler.com), see LICENSE file for licensing information
Adding source: ORA12102
INFO: reading schema from JSON for ORA12102
Adding target: T2
INFO: Oracle Analyser for ORA12102 in batch mode is starting
INFO: Kafka Writer with stdout output mode (test: 1) is starting
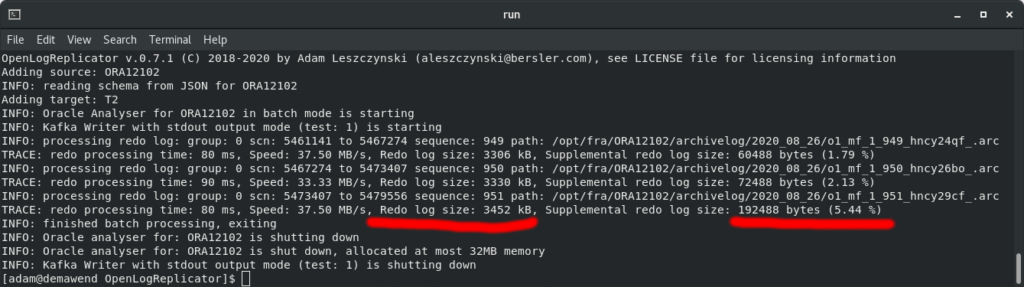
INFO: processing redo log: group: 0 scn: 5461141 to 5467274 sequence: 949 path: /opt/fra/ORA12102/archivelog/2020_08_26/o1_mf_1_949_hncy24qf_.arc
TRACE: redo processing time: 80 ms, Speed: 37.50 MB/s, Redo log size: 3306 kB, Supplemental redo log size: 60488 bytes (1.79 %)
INFO: processing redo log: group: 0 scn: 5467274 to 5473407 sequence: 950 path: /opt/fra/ORA12102/archivelog/2020_08_26/o1_mf_1_950_hncy26bo_.arc
TRACE: redo processing time: 90 ms, Speed: 33.33 MB/s, Redo log size: 3330 kB, Supplemental redo log size: 72488 bytes (2.13 %)
INFO: processing redo log: group: 0 scn: 5473407 to 5479556 sequence: 951 path: /opt/fra/ORA12102/archivelog/2020_08_26/o1_mf_1_951_hncy29cf_.arc
TRACE: redo processing time: 80 ms, Speed: 37.50 MB/s, Redo log size: 3452 kB, Supplemental redo log size: 192488 bytes (5.44 %)
INFO: finished batch processing, exiting
INFO: Oracle analyser for: ORA12102 is shutting down
INFO: Oracle analyser for: ORA12102 is shut down, allocated at most 32MB memory
INFO: Kafka Writer with stdout output mode (test: 1) is shutting downFor every processed redo log file you have information about exact byte size of all the sum of supplemental log groups. Even for third test – the size is about 192kB. This is 5,44% of the whole redo log file. I would expect more here.
Let’s repeat the same test but with columns defined as:
B char(500),
C char(500),
D char(500)With redo log files:
-rw-rw----. 1 500 500 7271424 Aug 26 07:53 o1_mf_1_953_hncy6fd8_.arc
-rw-rw----. 1 500 500 7335424 Aug 26 07:53 o1_mf_1_954_hncy6jhc_.arc
-rw-rw----. 1 500 500 8338944 Aug 26 07:53 o1_mf_1_955_hncy6mk3_.arcThe result would be:
$ ../runlocal.sh
OpenLogReplicator v.0.7.1 (C) 2018-2020 by Adam Leszczynski (aleszczynski@bersler.com), see LICENSE file for licensing information
Adding source: ORA12102
INFO: reading schema from JSON for ORA12102
Adding target: T2
INFO: Oracle Analyser for ORA12102 in batch mode is starting
INFO: Kafka Writer with stdout output mode (test: 1) is starting
INFO: processing redo log: group: 0 scn: 5480114 to 5486253 sequence: 953 path: /opt/fra/ORA12102/archivelog/2020_08_26/o1_mf_1_953_hncy6fd8_.arc
TRACE: redo processing time: 100 ms, Speed: 60.00 MB/s, Redo log size: 7100 kB, Supplemental redo log size: 60488 bytes (0.83 %)
INFO: processing redo log: group: 0 scn: 5486253 to 5492470 sequence: 954 path: /opt/fra/ORA12102/archivelog/2020_08_26/o1_mf_1_954_hncy6jhc_.arc
TRACE: redo processing time: 90 ms, Speed: 66.67 MB/s, Redo log size: 7162 kB, Supplemental redo log size: 73008 bytes (1.00 %)
INFO: processing redo log: group: 0 scn: 5492470 to 5498604 sequence: 955 path: /opt/fra/ORA12102/archivelog/2020_08_26/o1_mf_1_955_hncy6mk3_.arc
TRACE: redo processing time: 110 ms, Speed: 63.64 MB/s, Redo log size: 8142 kB, Supplemental redo log size: 1088488 bytes (13.05 %)
INFO: finished batch processing, exiting
INFO: Oracle analyser for: ORA12102 is shutting down
INFO: Oracle analyser for: ORA12102 is shut down, allocated at most 32MB memory
INFO: Kafka Writer with stdout output mode (test: 1) is shutting downEven for the third test – the supplemental log group total size is not very big – it reached just 13% of the whole redo log file.
The results may of course vary in your enviroment.