The task here is just to run native replication solution directly on Raspberry PI hardware. No emulators, no workarounds, no cheating. Let’s find out what is the redo log processing speed.
The key to this approach is using OpenLogReplicator as CDC engine and it’s offline mode. With this mode you can read redo logs without having to connect directly to the database using OCI.
Set up
I’m using the following configuration:
- Linux x86_64 – with Oracle 19c database
- Raspberry PI 3B (1GB RAM) – with OpenLogReplicator
- Linux x86_64 – with Kafka target
Database configuration
First I have set up the source database according to OpenLogReplicator requirements. I’m using USR1 login for initial database connection. For the test I have used the login USR1.
The database holds the redo logs in FRA which is located in /opt/fra.
Raspberry PI set up
This set is very easy, just download & compile the code:
git clone https://github.com/Tencent/rapidjson
git clone https://github.com/edenhill/librdkafka
cd librdkafka
./configure --prefix=/opt/librdkafka
make
sudo make install
cd ..
git clone https://github.com/bersler/OpenLogReplicator
cd OpenLogReplicator
autoreconf -f -i
./configure CXXFLAGS='-O3' --with-rapidjson=/home/pi/cdc/rapidjson --with-rdkafka=/opt/librdkafka
makeSince there is no Oracle Client for Raspberry PI available – I am building OpenLogReplicator without OCI module.
To be able to read redo log files from database FRA I have mounted the the following disks on PI:
mkdir /opt/fra
sudo sshfs -o Ciphers=aes128-ctr,Compression=no,allow_other,cache=no,noauto_cache,IdentityFile=/home/pi/.ssh/id_rsa oracle@db:/home/fra /opt/fraSchema & test
I have used the following schema for testing:
create table usr1.adam1(
a numeric,
b number(10),
c number(10, 2),
d char(10),
e varchar2(10),
f timestamp,
g date
);And the following test:
alter system switch logfile;
begin
for i in 1 .. 20000 loop
insert into usr1.adam1 values(i, 0010, 10.22, '010', '010', to_date('2019-08-01 12:34:56', 'YYYY-MM-DD HH24:MI:SS'), null);
commit;
end loop;
end;
/
alter system switch logfile;The log switches are used here for performance measuring purposes. I can run the whole batch and later measure how long this particular redo log have been processed.
First run
The first run of CDC is made on a Linux box – so that OpenLogReplicator can read the schema. During the run 2 files are created: ORA19800-chkpt.json and ORA19800-schema.json were created. I have copied both files to Raspberry PI. I have used the following JSON configuration file:
{
"version": "0.7.17",
"trace": 2,
"trace2": 32,
"sources": [
{
"alias": "S1",
"name": "ORA19800",
"reader": {
"type": "offline",
"path-mapping": ["/opt/fra", "/opt/fra"]
},
"format": {
"type": "json"
},
"memory-min-mb": 32,
"memory-max-mb": 512,
"tables": [
{"table": "USR1.ADAM1", "key": "a"}]
}
],
"targets": [
{
"alias": "T1",
"source": "S1",
"writer": {
"type": "kafka",
"topic": "O112A",
"brokers": "192.168.10.30:9092"
}
}
]
}The trace parameters have no effect on the way transactions are processed – they just control the verbose output parameters. In particular trace2 displays some performance information I am interested in.
The hardware has just 1GB of RAM so I have limited the maximum usage of OpenLogReplicator to 512MB.
First run on Raspberry PI:
cd /home/pi/cdc
export LD_LIBRARY_PATH=/opt/librdkafka/lib
./OpenLogReplicator/src/OpenLogReplicatorAnd … it works. During the test I have achieved about 3,8MB/s speed of redo log parsing which is … not that bad 🙂
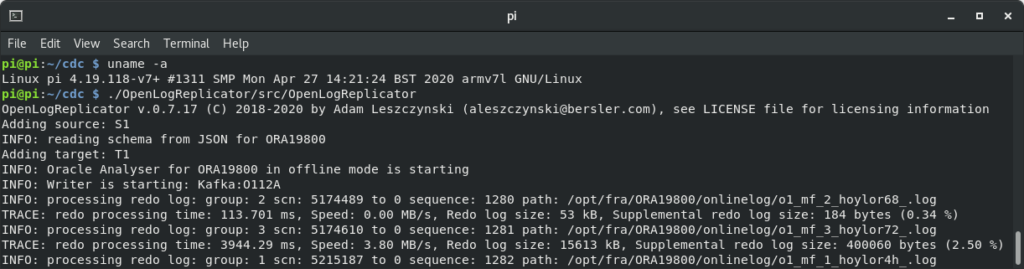
And transactions have actually arrived to Kafka:
...
{"scn":5215175,"tm":18446744072965846208,"xid":"7.14.3472","payload":[{"op":"begin"}]}
{"xid":"7.14.3472","payload":[{"op":"c","schema":{"owner":"USR1","table":"ADAM1"},"rid":"AAAGhsAAEAAABOkACz","after":{"A":19999,"B":10,"C":10.22,"D":"010 ","E":"010","F":1294800256}}]}
{"xid":"7.14.3472","payload":[{"op":"commit"}]}
{"scn":5215177,"tm":18446744072965846208,"xid":"9.7.3321","payload":[{"op":"begin"}]}
{"xid":"9.7.3321","payload":[{"op":"c","schema":{"owner":"USR1","table":"ADAM1"},"rid":"AAAGhsAAEAAABOkAC0","after":{"A":20000,"B":10,"C":10.22,"D":"010 ","E":"010","F":1294800256}}]}
{"xid":"9.7.3321","payload":[{"op":"commit"}]}